《第七章》简单的性能优化
-
开发中或者是正在运行的系统性能显著恶化的场合,需要进行性能优化。当听到性能优化时,有些人可 能会感觉到非常困难,如果使用OB的话,通过使用索引或者内存等可以非常简单的进行性能优化。这篇 文章将要介绍怎样使用OB简单的使性能优化。
■性能优化是什么
EC系统的“3秒钟规则”
假设在EC网站上,访问网站的顾客都必须要等待三秒钟的响应时间,这个时间被称为“3秒钟规则”。 如果响应时间在三秒钟以上的话,顾客就会认为这个网站服务慢,有可能会导致商业机会的丢失。不用 说EC网站的例子,为了有效的推行业务,系统的性能是非常重要的。系统中并不仅仅要安装重要的功能 (功能需求),还必须要知道响应时间是多少,单位时间内电脑的处理量、通信线路的数据传送量等 (非功能需求)。
数据库即使是在系统开发的后端,也有调整响应时间的性能优化。数据库性能优化就是针对响应时间 非常慢的场合实施的对策。OB有很多功能支持性能优化。
性能优化的流程
以下是包含数据库的一般的性能优化的流程。
1.调查
性能优化首先要从性能测定和找到产生问题的地方开始。要把系统构成和应用设计作为优化对象进行确认和测定,调查延迟原因。
测定方式除了响应时间之外,还可以查看SQL实行计划中“cost”使用量。
2.设定目标值
接下来,我们要知道要把性能改善到何种程度。进行性能优化有很多种手段,要是全部实施的话将是没完没了的,所以最重要的是设定目标值。要考虑系统至少需要把性能调整到何种程度,例如EC网站要把响应时间缩短到3秒以内等等。
3.研究改善对策
决定了目标之后就要研究改善对策了。应用逻辑有问题的话就把算法修改成更高效的,SQL有问题的话就把表的关联尽量减少。还有给表设定合适的索引,把外部的应用处理用存储过程的形式。尽量找到达成目标的最有效的方法。
4.实施/调整
决定了改善对策之后,进入实施阶段,看能否达成目标。如果目标达成了,性能优化就成功了。也有实施对策之后没有达成目标的情况,这时就要重复一遍以上的步骤,改变改善对策。
假如有多个改善对策的话,可以改变改善方法或者是追加改善方法。也许还会遇到其他的瓶颈,这时要返回去重新进行原因分析。在达成目标之前,以上的步骤要循环1~4圈。
所谓瓶颈就是数据库服务器的内存不足,或者SQL的处理速度等数据库外部的性能调整。本篇文章介绍如何使用OB进行数据库优化。
■SQL处理速度的改善(优化索引)
最初运行良好的系统突然变的非常慢,这通常被认为是因为数据的增加使响应速度降低。像这种场合,“优化索引”多次发挥了效果。
优化索引就是给表做成合适的索引,改善性能的方法。如果表中没有索引的话,检索时就是从表所有数据中进行搜索(全表搜索)。进行全表搜索时,如果数据量很大的时候访问速度就会非常慢。这时,如果给表设置合适的索引的话,从大量的数据中有目的的高效的进行搜索,这就可以改善性能。以下是一般优化索引的顺序和OB的功能。
1.抽出运行慢的SQL-->SQL缓存
2.测量SQL的性能-->实行计划
3.做成合适的索引-->索引顾问
使用“SQL缓存”找到SQL性能低下的原因。用“实行计划”测量性能。用“索引顾问”决定改善对策。
抽出速度慢的SQL“SQL捕捉”
接下来要具体介绍“SQL捕捉”的操作方法。为了进行索引优化,首先要从所有的SQL文中找到速度慢的SQL。
SQL捕捉,是跟踪SQL一览表示处理速度和测定结果的功能。此功能在“工具”菜单的“SQL捕捉。
SQL捕捉是为了调查正在运行的SQL所实施的跟踪。跟踪就是对正在运行的SQL的记录。初次启动SQL捕捉时,显示的是跟踪文件存在的文件夹对话框。
关于跟踪文件夹一定要指定成Oracle数据库服务器上跟踪文件存在的文件夹。通常是“Oracle Home/ADMIN/ORCL/UDUMP”。
一定要指定成数据库服务器上的文件夹。安装OB的客户端机器和数据库服务器不同场合,利用操作系统的网络共享功能,指定成客户端和服务器都能参照的文件夹。
TIPS 想要变更跟踪文件存在的文件夹时
在主菜单的“SQLcatch”-->“选择跟踪文件夹”中指定即可。
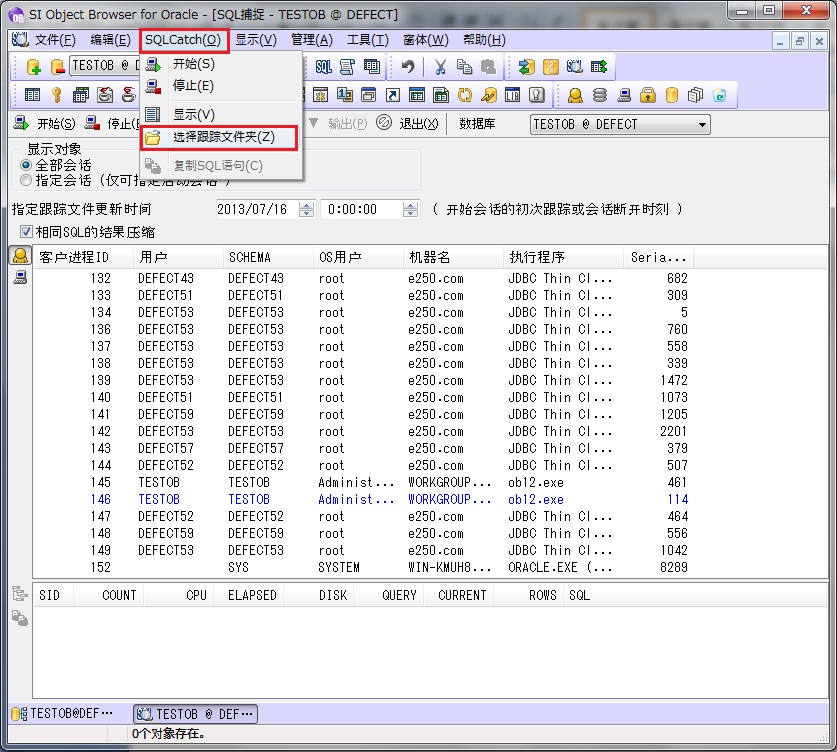
指定了跟踪文件夹之后,SQL缓存画面就表示出来了。
SQL跟踪的结果被做成日志文件保存在刚刚设置的文件夹内。
点击画面左上角的“开始”按钮,开始跟踪。显示跟踪实行画面,我们要指定对数据库全体进行跟踪还是对个别session进行跟踪。如果要对个别session进行跟踪的话,要选择想要调查的应用对应的session,并且还要在应用中执行登录操作等,做成数据库session。
如果选择对数据库全体进行跟踪的话,就是对所有的session进行跟踪。但是,要把初期化参数“SQL_TRACE”设置成TRUE。
跟踪开始后,可以回到应用页面进行操作。例如,EC网站中商品检索画面缓慢的话,可以执行商品检索操作。这时,正在运行的SQL会记录在跟踪日志中。
操作完成之后,返回到OB,点击“停止”,停止跟踪,接下来确认一下跟踪结果。点击SQL缓存画面的“表示”按钮,跟踪结果画面显示出来。
COUNT:SQL文实行或者是解析的次数
CPU:SQL进行解析/实行/取得操作,CPU耗费的时间
ELAPSED:经过时间
DISK:实行中读出物理块的次数
QUERY:SQL语句要求的总读取次数
CURRENT:SQL语句要求的正在执行的读取次数
ROWS:实行中处理的行数
SQL:实行的SQL文
CPU列代表处理速度,点击这些列使他们按照处理速度排序,找到速度慢的SQL。
测量SQL的性能
找到速度慢的SQL之后,在SQL实行画面的“实行计划”功能可以测量SQL的性能。
实行计划”就是在SQL实行之前数据库内部进行的处理。例如,如果是SELECT的话,多表结合的方法、顺序,是否使用索引取得数据,这些都是基于数据库内部的信息决定的。在数据库内部具有决定实行计划功能的部分叫做“优化器”。
在SQL实行画面中点击“实行计划”按钮,“实行计划”按钮是on的状态时,输入SQL文,点击“实行” 按钮,此时进行的是SQL解析,实行计划表示出来。
TIPS 从SQL缓存画面也可以取得实行计划在SQL缓存画面选中某行点击鼠标右键,从弹出的对话框中选择“实行计划”即可。
在这之中,索引优化最重要的是以下两点。
COST实行计划最右面的列就是COST。COST就是数据库处理SQL的负荷,是一项性能指标。COST的单位不是秒,1COST相当于多少秒是受服务器的硬件影响的,所以不能进行严密的换算,可以相对的进行比较。例如,实际上系统的响应时间是30秒,目标值是3秒,只需把COST值缩小10倍就可以了。
是否使用索引进行全表搜索时(没有使用索引的场合),实行计划的行是红色的。这样就可以知道还可以进行索引优化。
做成合适的索引 “索引顾问”从实行计划得知没有使用索引时,可以使用OB的索引顾问功能做成索引。如果不使用索引顾问还可以在索引画面手动做成,但是并不是索引使用的越多就越好。
例如“书籍”表,索引是“目次”。一般读者只想读书的一部分的话,首先要参照目次,找到想看的内容的页数。但是如果书只有20几页的话,读者就不需要看目次,直接找到相应的页数。反过来,如果目录有100多页的话,谁也不会使用这么麻烦的东西。
决定实行计划的优化器也认为当记录数很少的时候最好不要使用索引。并且,当索引对象的列很多的时候,因为索引占的空间很大,也不要使用索引。为了作成合适的索引必须要考虑这些问题。但是,使用OB的索引顾问的话,即使不知道这些规则,也可以做出合适的索引。
在使用索引顾问之前要使用索引顾问,需要做两项准备工作。第一个是作成足够的数据。
前面说到,判断使用索引还是没有使用索引的重要的指标就是数据量。所以,当数据很少时,要使用数据生成工具生成一些数据。
还有就是要获取最新的统计信息。优化器统计表的行数时并不是每次都使用COUNT文,而是从统计信息中取得行数。如果统计信息不是最新的话,优化器就不能做出最好的判断。
获取最新的统计信息的方法是,在对象列表中选中一个表点击鼠标右键,选择“统计信息”,更新画面显示出来。点击“开始”就能取得最新的统计信息。Ctrl+A可以选中所有表。
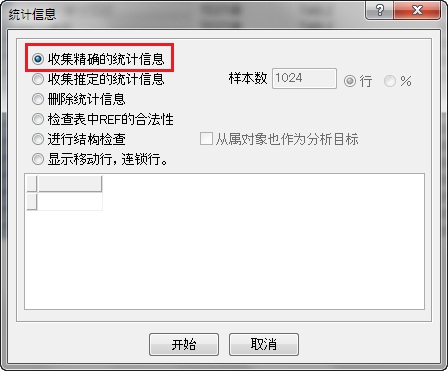
在统计信息画面有很多选项,因为我们的目的是优化索引,所以选择“收集正确的统计信息”。
TIPS 基于规则、基于COSTOracle的优化器有基于规则和基于COST两种模式。上面说到优化器决定实行计划的时候要考虑记录数,这严密的说应该是基于COST场合需要做的。当实行计划是基于规则,则不用考虑记录数,需要遵循一定的规则做出实行计划,例如,使用WHERE句的列是否包含在索引的对象列中。
优化器的模式是基于规则的时候,不需要做成数据和更新统计信息,一般不推荐使用基于规则的模式。刚才图书的例子,参考统计信息的基于COST的方法更好一些。因此,在Oracle10g以后,OB废弃了基于规则的优化器模式。
使用哪个模式可以在初期化参数“OPTIMIZER_MODE”中查询。
准备工作完成之后,启动索引顾问。“工具”-->“索引顾问”。
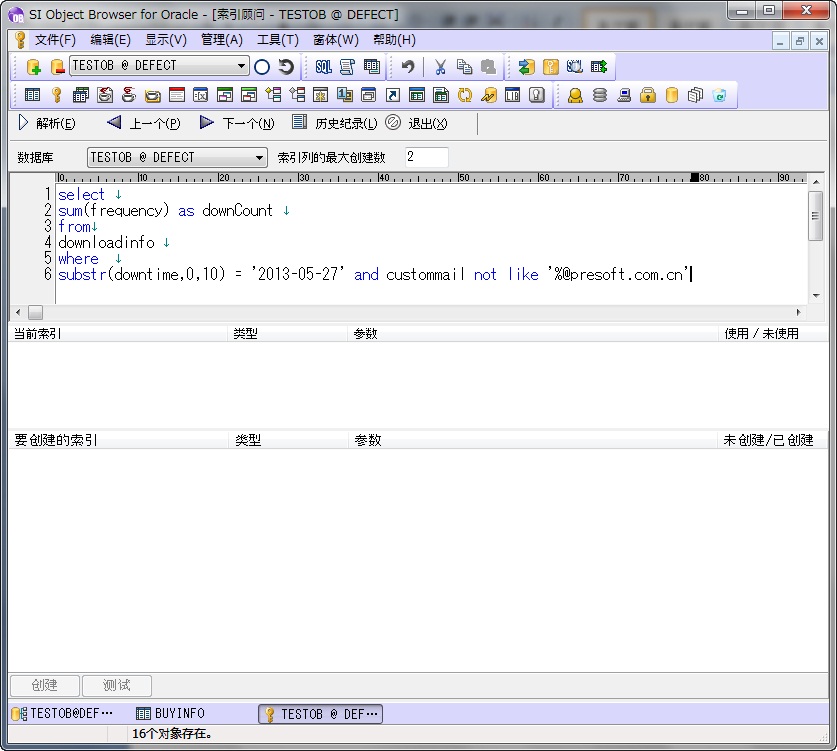
在索引顾问画面有“输入SQL”,“现在的索引”,“做成的索引”3部分。首先在最上方的“输入SQL”栏中写入要优化的SQL。索引顾问页面和SQL实行画面一样,有履历管理的功能。因为这个履历和SQL实行画面的履历是共有的,所以想在SQL实行画面查询实行计划的话,点击“前”或者是“履历”按钮,就可以呼出同样的SQL。
SQL输入完成后,点击“解析”按钮,在页面中间的“现在的索引”栏内表示的是表和附加在表上的索引的使用状况。没有被使用的索引用红色表示,如果索引不需要了,可以用DELETE键或者点击鼠标右键“消除”进行删除。
在页面下面的“做成的索引”栏中表示的是每个表中被认为是有用的索引。这个栏中表示的是没有被做成的索引,选择一项点击“做成”按钮,索引就被做成了。

但是,我们不知道这样做成的索引是否一定被使用。
索引顾问是解析SQL,得出候补的索引,但是根据记录数的不同,做成的索引是否被优化器使用是不一样的。因此,OB有了比较索引做成前后的COST数的功能。点击“测试”按钮,得到索引做成前和做成后的COST数。

如果做成前和做成后的结果不一样的话,就证明使用了索引。如果结果没变的话,就是即使做成了索引也没有被使用。和实行计划功能一样,性能是用COST表示的,不仅仅是索引的使用状况,根据变化也可以知道性能提高了多少。用户可以按照候补索引的顺序依次测试,选择结果最好的索引。
索引做成之后,会自动进行再解析,最后做成的索引会出现在“现在的索引”栏目中,请确认索引是否被使用。
到此为止索引优化就完成了。
TIPS 不要使用过多的索引
是每个SQL决定索引是否被使用,最合适的索引是什么依据SQL的不同而不同。一个表不可能只对应一种SQL。即使是不常被更新的主表,除了从管理工具访问之外,还可能和事务内的其他表结合。如果做成多个SQL共同使用的索引很困难的话,那么就给一个表设置多个索引。
但是,索引过多也不好。索引在表中的数据更新的同时会进行再构筑,如果索引多时,就会增加表更新时的负荷。因此,最好是把想要改善性能的SQL和频繁使用的SQL作为索引的对象。
■资源的优化
前面介绍的是通过优化SQL改善性能。如果是因为随着数据量的增加而导致性能恶化的话,这些方法是有效的。但是也有可能是因为内存不足输入输出增加,CPU使用到达界限,数据库服务器的资源不足等。OB有改善这些问题产生的性能恶化的“资源优化”功能。资源优化按照下面的顺序进行。
1.资源状况测定 “性能信息”
2.资源优化 “初期化参数变更”
首先参照Oracle的系统统计和I/O统计等统计信息,然后更改Oracle资源设定中初期化参数的信息。
资源状况测定OB中使用“性能信息”来调查资源不足的原因。“性能信息”画面在“管理”菜单中。

性能信息画面有系统统计和I/O相关的统计等一些项目。重要的项目在前面用 
表示,选择 这个项目就会显示项目的说明和改善方法。 但是多数情况下是确认这些参数在性能刚开始降低时候的值,即使是有专业知识的专家在性能已经恶化的状态下找出原因也是非常困难的。所以,OB提供了定期保存性能信息的功能。保存性能良好时参数的值,这样就可以和性能恶化时的参数值进行比较。
这个功能在“工具”-->“选项”-->“详细设置”中,选择“DB连接结束时自动保存”,设置保存时间间隔。OB终了时如果到了保存间隔的话就会把参数自动保存起来。例如把保存间隔设成30天的话,就是每30天进行一次保存。

被保存起来的信息在性能信息画面表示,可以把性能恶化前和恶化后的值进行比较。
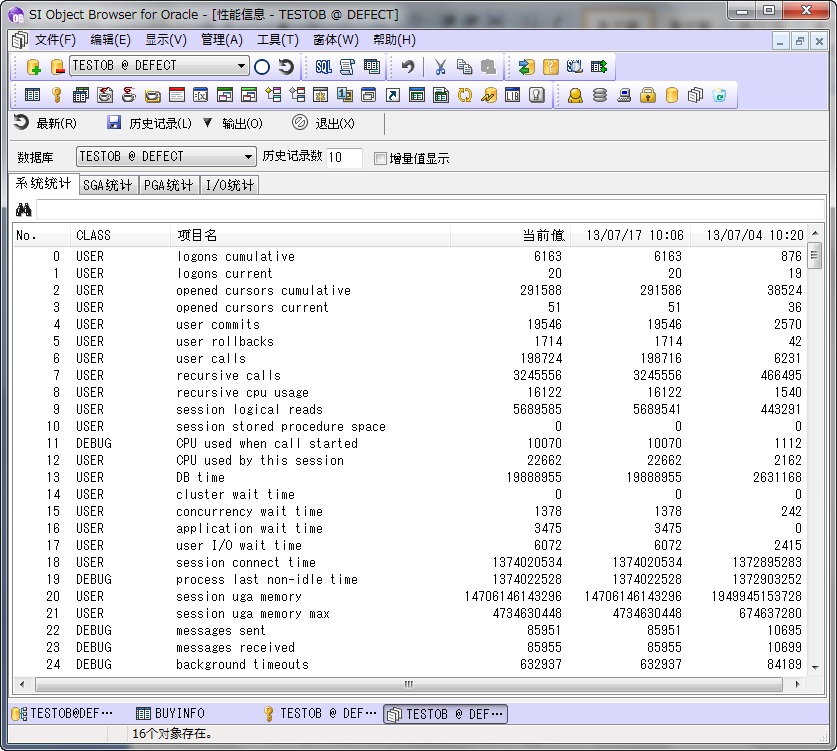
改善初期化参数在“性能信息”中判定性能恶化的原因是内存等资源不足的情况下,可以使用改变初期化参数的方法进行性能改善。打开“管理”-->“数据库信息”,打开“初期化参数”选项卡。
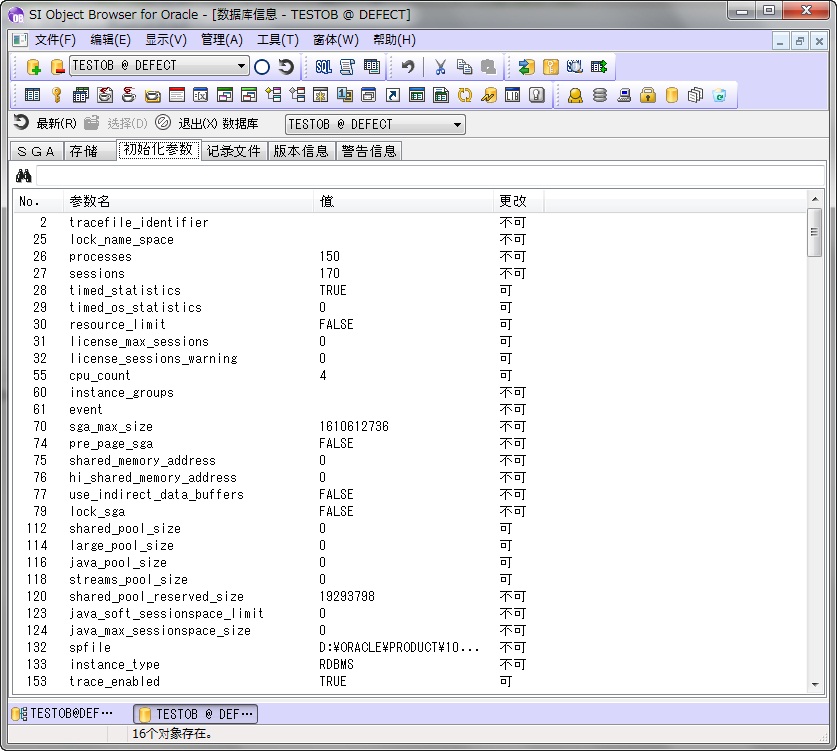
以下是和性能改善相关的具有代表性的参数。
SGA_MAX_SIZE: SGA的最大值。SGA(System Global Area)是数据库缓冲区高速缓存和共享池等服务器进程使用的内存区。 DB_CATCH_SIZE: 数据库缓冲区高速缓存大小。它的值越大,访问数据的速度越快。 SHARED_POOL_SIZE: 共享池的大小。它的值越大,程序库缓存的命中率越高,SQL的实行速度越快。 JAVA_POOL_SIZE: JAVA池的大小。它的值越大,JAVA存储过程等的实行速度越高。 SORT_AREA_SIZE: 排序使用的内存容量。它的值越大,排序的速度越快。 LOG_BUFFER: 把REDO信息写入REDO日志文件时使用的内存容量。它的值越大,写入REDO日志文件的等待时间就越少。
根据Oracle版本的不同,这些项目有可能能修改也有可能不能被修改。“变更”列说明了是否能被修改。
当变更的状态是“可能”时,双击“值”,会出现变更对话框。
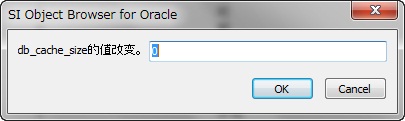
“不能”的场合可以更改init.ora或者SPFILE等设定文件,并重新启动数据库。
修改初期化参数是性能优化中非常容易执行的方法,因为要增加Oracle使用的内存空间,所以要先确定服务器剩余的内存容量。
■表访问的优化
表领域的分割
最后介绍一下其他的优化方法。SQL的处理速度非常慢的时候尝试用索引优化的方法,但是却不能把性能提高到目标值。这时,可以使用提高表访问速度的组合分区的方法。
分区是硬盘的读取和写入同时进行的技术。数据库有表领域的概念,表领域实际上是和存放数据的操作系统上的文件有关。表和表领域是从属关系,一个表可能属于一个表领域,但是如果进行分区的话,就可以把表分成几个表领域存放。这样就可以使读取和写入并列化,从末端改善表访问。
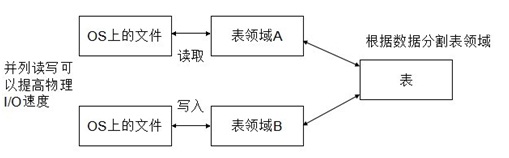
分区的顺序
要做成表领域选择“管理”菜单-->“表领域信息”。在表领域一览画面点击“新建”按钮,显示新建画面。

至少要输入的项目是“表领域名”,“文件地址”,“大小”。“文件地址”是服务器上的地址。“大小”是知道表的容量之后设定的。除此之外的项目都不是必须设定的。设定完成后,点击“作成”按钮,表领域就做好了。请按需要添加表领域的数量。
TIPS 调查表领域所需的大小
表领域必须的数据大小大概是表中各列数据的长度和总数据行数的乘积。但是,严密来说表的block size和INITRANS等表领域相关的设定也是有影响的。把这些也考虑进去计算表领域大小的工具是Oracle免费提供的。
http://otn.oracle.co.jp/document/estimate/index.html
“SI Object Browser ER”也提供了估算表领域大小的功能。表领域做成之后,在表画面的“领域信息”选项卡内进行设定。表做成时的存放方法是“通常”,这样可指定的表领域就只有一个,如果把存放方法改成“范围分区”,“列表分区”,“散列分区”中的任何一个,就可以分区化。
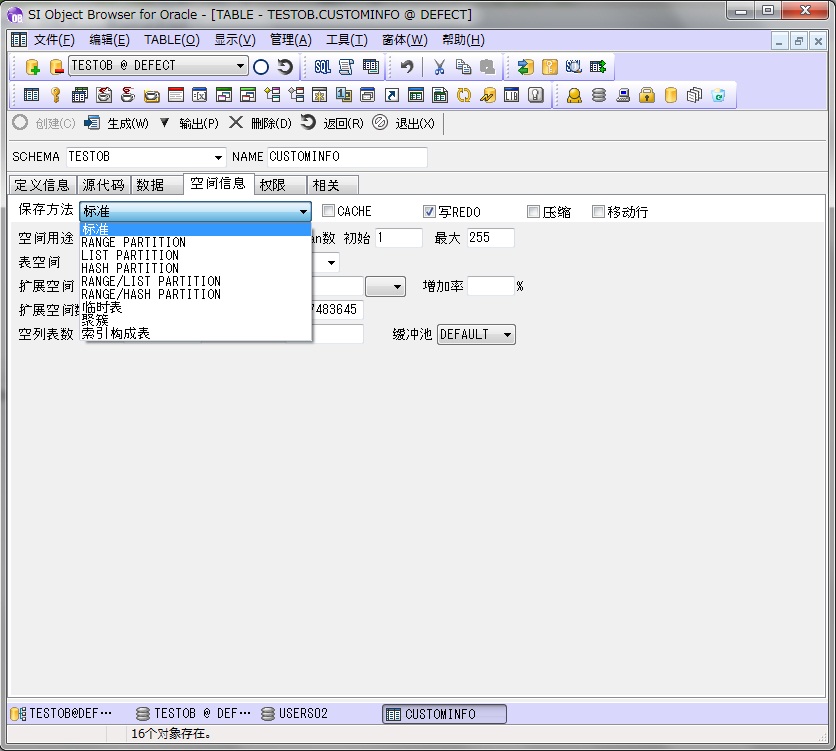
范围、列表、散列的不同之处是各条数据分配方法的不同。分区的场合指定表中的一列是主键,根据主键对应的值把数据分配在各个分区中。以下是分配方法。
范围分区
根据值的范围存放在不同的表领域中的方法。指定上限值栏内各个表领域包含的数据的范围来分配表领域。例如,当想根据价格等数值类型、日期类型分配表领域的时候使用。
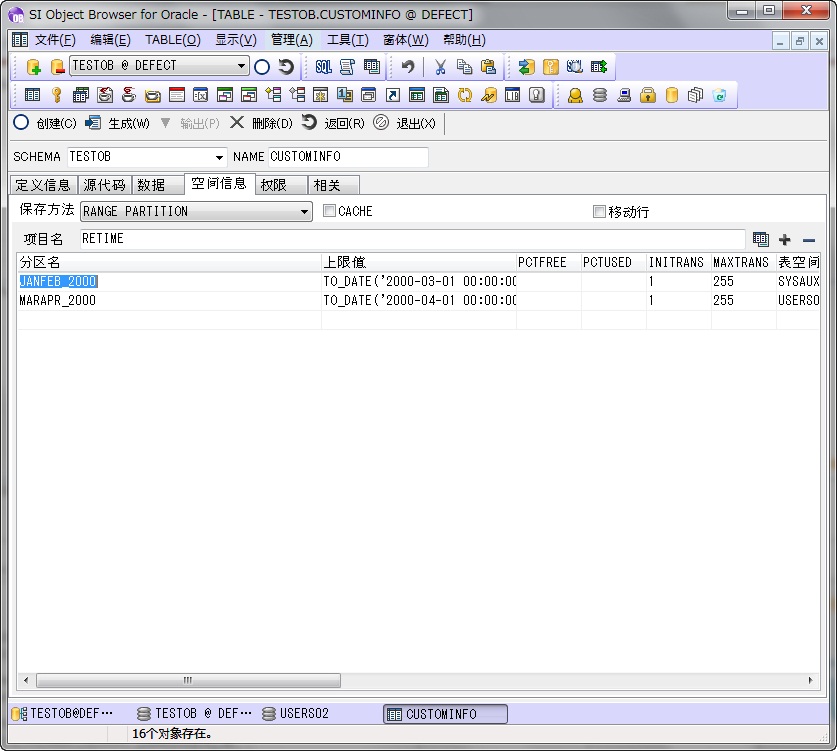
列表分区
根据值指定表领域。例如,当想根据价格等数值类型、日期类型分配表领域的时候使用。当输入的值是数据库标识等的时候使用。

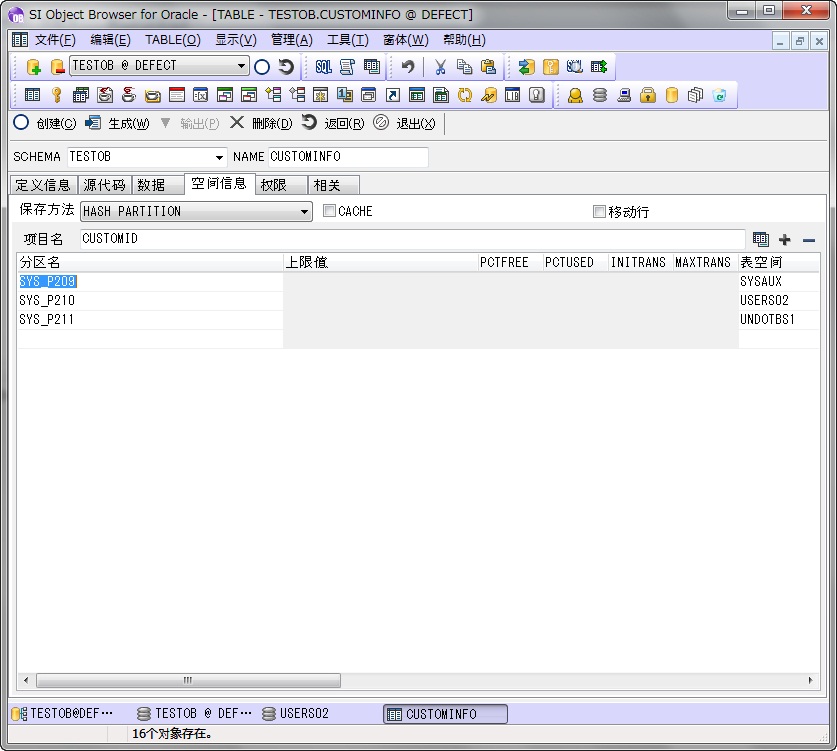
散列分区
当不根据范围和值,随机分配表领域的时候使用。“散列”就是通过“MD5”和“SHA-1”等算法从某个值生成特定的值的算法。在Oracle内部通过散列算法生成值,并根据值分配表领域。当存放的值不一定的场合使用此方法。当不根据范围和值,随机分配表领域的时候使用。“散列”就是通过“MD5”和“SHA-1”等算法从某个值生成特定的值的算法。在Oracle内部通过散列算法生成值,并根据值分配表领域。当存放的值不一定的场合使用此方法。
TIPS 综合分区
Oracle中有多种分区方法,我们还可以使用“范围、列表分区”等两种分区方法组合在一起的“综合分区”。
选择了综合分区之后,在分区设定栏的下边会显示叫“子分区”的设定栏。在子分区中可以指定值和表领域。

但是,综合分区的方法在Oracle8i以前的版本不能使用。9i和10g的版本只可以选择“范围、列表分区”或者“范围、散列分区”。11g没有限制了,但是散列只可以作为子分区设定,例如,是不能设定“散列、列表分区”方法的。所以现在可以设定的分区方式有6种,以下是可以组合的分区方式(横列是子分区)。
列表 列表 列表 范围 11g~ 9i~ 9i~ 列表 11g~ 11g~ 11g~ 以上就是使用OB进行的简单的性能优化的方法。要进行性能优化还有一些其他的方法,例如使用存储过程或者是物化视图。首先请先试试上面的方法吧。